
Introduction
The UK Gaia Data Mining Platform is a science platform for large-scale exploitation of the publicly released Gaia data products. It provides a notebook-based environment to enable users to bring their code to the large volume of data which is co-located with distributed compute facilities provided via the Apache-Spark ecosystem. The Gaia DMP is particularly suited to scale-out workflows requiring some level of high performance and/or high throughput, for example:
- bulk trawls through datasets
- large-scale statistical analyses
- machine learning applications
without having to download large volumes of data.
What the service can do
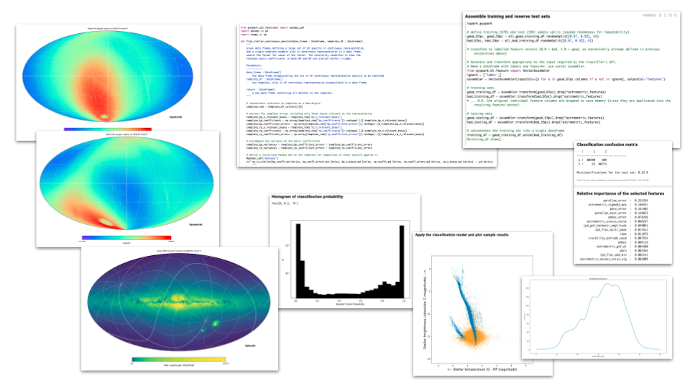
The service allows users to run their code in a distributed execution environment co-located with the data. This provides for example
- the means for quick and easy visualisation of arbitrary catalogue quantities over the whole sky
- a high degree of end-user programmability for large scale statistical analysis
- easy interfaces to common Machine Learning algorithms
- straightforward access to the bulk Gaia data products (presently amounting to ~10 TB).
How to get access to the system
For a user account on the Gaia DMP please email gaiadmp-support@roe.ac.uk
When your account is set up access the system here.
Frequently Asked Questions
Q1. What language(s) does the platform support?
A1: Python is the primary language supported by the Gaia DMP. (Other interpreters may be added and supported if there is sufficient demand.)
Q2. What datasets are hosted on the platform?
A2: Currently Gaia E/DR3 is hosted on the platform along with DPAC cross-matches to, and original catalogue records from PanSTARRS1, 2MASS and AllWISE.
Q3. Do I need to have experience in distributed computing to use the platform?
A3: No. Example notebooks are provided that illustrate typical workflows and explain how to use the PySpark data frame Application Programming Interface. This hides much of the raw Spark distributed computing syntax from the novice user. PySpark even has a familiar SQL interface to make the transition from using an ADQL-based archive system as easy as possible for beginners. All that is really required to get started is a basic knowledge of Python and structured querying of data (e.g. SQL). Familiarity with Numpy, Pandas and vectorised processing techniques will help in getting the most out of the system.
Q4. Why Zeppelin notebooks as opposed to the more common Jupyter style?
A4: The user interface employs Zeppelin notebooks as these are an integral part of the Apache Spark ecosystem and as such require fewer interface layers. Zeppelin also has the advantage of offering language interpreters other than Python, and even the possibility to mix those within a single notebook. Note that you can import and export Python notebooks in ipynb format on the Gaia DMP.
Acknowledgements
We are grateful to Gaia DPAC colleagues at the University of Barcelona for developing the prototype Gaia Data Analytics Facility on which the UK Gaia DMP is based. We gratefully acknowledge help and support from all our Gaia DPAC colleagues in developing this service.
Computing facilities for development and hosting are provisioned via the UK e-Infrastructure for Research and Innovation at the Science and Technology Facilities Council (the IRIS project). We thank IRIS for generous allocations of computing resources and we are grateful to the University of Cambridge DiRAC service for providing them.
Staff funding for the development and operation of the UK Gaia Data Mining Platform is provided by the UK Science and Technology Facilities Council.